【写在前面】
这是2023-2024春季学期操作系统课程有关xv6 lab部分的实验报告,参考了很多网络资源,解释也不一定正确,仅作为留档,参考需谨慎。
Lab 地址:6.1810 / Fall 2024
参考:
yali-hzy/xv6-labs-2024: MIT 6.1810 assignments
[mit6.s081] 笔记 Lab8: Locks | 锁优化 | Miigon’s blog
[MIT 6.s081] Xv6 Lab9 Lockss 实验记录 | tzyt的博客
Memory allocator
在开始实验前,kalloctest 的输出:
实验任务分析
实验任务是优化 xv6 操作系统的内存分配器,以减少锁争用。具体来说,程序 user/kalloctest 会对 xv6 的内存分配器施加压力,通过三个进程不断扩展和收缩它们的地址空间,从而产生大量的 kalloc 和 kfree 调用,而 kalloc 和 kfree 需要获取 kmem.lock 锁。实验要求我们重新设计内存分配器,避免使用单一的锁和空闲列表,采用每个 CPU 对应一个空闲列表并配备独立锁的方式,并在需要时实现不同 CPU 之间的内存窃取,以减少锁争用。
具体要求:
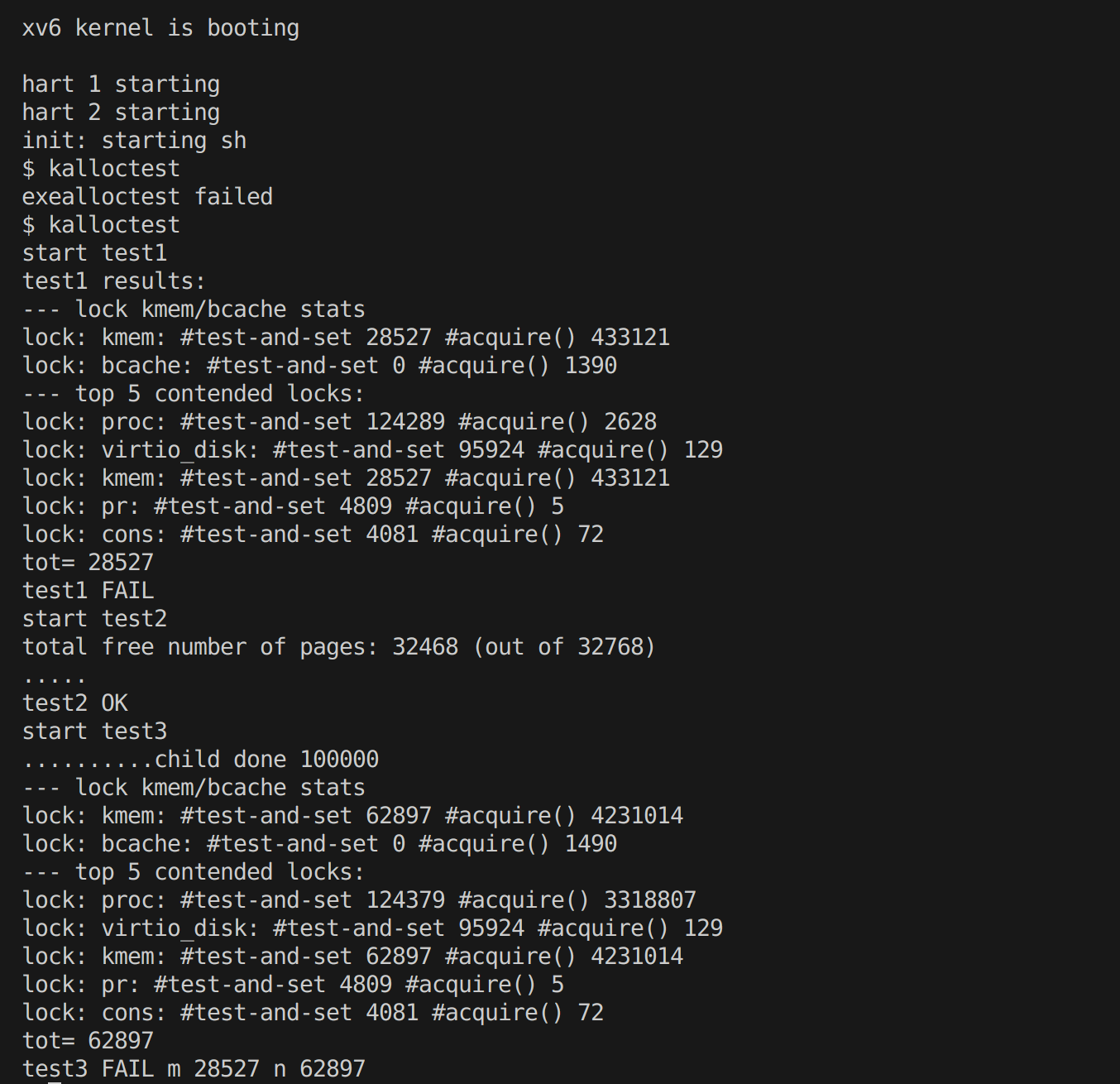
Your job is to implement per-CPU freelists, and stealing when a CPU’s free list is empty. You must give all of your locks names that start with “kmem”. That is, you should call initlock for each of your locks, and pass a name that starts with “kmem”. Run kalloctest to see if your implementation has reduced lock contention. To check that it can still allocate all of memory, run usertests sbrkmuch. Your output will look similar to that shown below, with much-reduced contention in total on kmem locks, although the specific numbers will differ. Make sure all tests in usertests -q pass. make grade should say that the kalloctests pass.
相关源码分析
kmem
kmem 是一个全局的内存管理结构,用于管理内核内存的分配和释放。它包含一个锁和一个空闲链表,用于保护和管理内存分配的同步操作。在修改前的 xv6 实现中,kmem 是一个单一的结构体实例,所有 CPU 都共享同一个 kmem 结构体,这会导致多 CPU 环境下锁争用严重。
kinit 函数
- 初始化锁:
initlock 函数初始化一个自旋锁,用于保护内存分配器的空闲链表,防止多个 CPU 或线程同时访问导致数据不一致。
- 初始化内存范围:
freerange 函数将从 end 到 PHYSTOP 的物理内存标记为可用内存,end 是内核代码和数据的结束地址,PHYSTOP 是物理内存的上限。
kfree 函数
- 参数检查:检查传入的物理地址是否对齐、是否在有效范围内,如果无效则调用
panic 函数终止系统。
- 填充内存:使用
memset 函数将释放的内存页面填充为特定值(1),用于检测是否有悬垂指针(dangling pointer)引用已释放的内存。
- 更新空闲链表:获取锁后,将释放的内存块添加到空闲链表的头部,然后释放锁。
kalloc 函数
- 获取空闲内存块:获取锁后,从空闲链表中取出第一个内存块,并更新空闲链表的头部。
- 填充内存:如果成功分配到内存块,将其填充为特定值(这里是 5),用于检测是否有悬垂指针引用已释放的内存。
- 返回内存块指针:返回分配的内存块的指针,如果没有可用内存块则返回空指针。
NCPU
根据提示:“You can use the constant NCPU from kernel/param.h”,查阅param.h可知 NCPU 常量表示最大 CPU 数量,可以用于设置kmem大小。
1
|
#define NCPU 8 // maximum number of CPUs
|
实验任务实现思路
- 把用于管理内核内存的分配和释放的结构体
kmem修改为一个大小为NCPU的数组,确保在最大CPU数量时,每个CPU都能有独立的空闲列表和对应的锁。
- 根据修改后的
kmem对照源码的功能修改相关的函数。与源码主要的区别在于:
- 初始化锁时需要命名不同的名字。根据提示:“Have a look at the
snprintf function in kernel/sprintf.c for string formatting ideas. ”,可以使用snprintf 函数
- 因为有多个CPU多个锁,操作前需要获取当前CPU的标识符并且获取当前CPU对应的锁
- 根据提示:“The function
cpuid returns the current core number, but it’s only safe to call it and use its result when interrupts are turned off. You should use push_off() and pop_off() to turn interrupts off and on. ”,在获取 CPU ID 的过程中,需要禁用中断以确保操作的原子性,避免在多 CPU 环境下出现竞态条件)
- 增加内存窃取机制:当
kalloc 函数中无法获取到获取空闲内存块时,遍历其他CPU的空闲链表窃取空闲的内存块。为了代码编写方便且尽量减少对其他 CPU 空闲链表的结构改变,窃取时选择其他CPU空闲链表从头到遍历的第一个中断处的空闲内存块,即找到的第一段连续内存块。
修改代码(kalloc.c)
修改结构体kmem为大小为NCPU的数组
1
2
3
4
|
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
|
修改kinit()
1
2
3
4
5
6
7
8
9
10
11
|
void
kinit()
{
//initlock(&kmem.lock, "kmem");
char lock_name[10]; // 存储名字的数组
for(int i=0;i<NCPU;i++){
snprintf(lock_name,10,"kmem_%d",i); // 命名为'kmem_i'
initlock(&kmem[i].lock,lock_name); // 为每个CPU初始化自旋锁
}
freerange(end, (void*)PHYSTOP);
}
|
修改kfree()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
// acquire(&kmem.lock);
// r->next = kmem.freelist;
// kmem.freelist = r;
// release(&kmem.lock);
push_off(); // 临时禁用中断,避免获取CPU的标识符时被打断
int cpu = cpuid(); // 获取当前CPU的标识符
pop_off(); // 恢复中断
acquire(&kmem[cpu].lock); // 获取当前CPU对应的锁
r->next = kmem[cpu].freelist;
kmem[cpu].freelist = r; // 将释放的内存块添加到当前 CPU 的空闲链表中
release(&kmem[cpu].lock); // 释放锁
}
|
修改kalloc()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
void *
kalloc(void)
{
struct run *r;
// acquire(&kmem.lock);
// r = kmem.freelist;
push_off();
int cpu = cpuid(); // 获取当前CPU的标识符
pop_off();
acquire(&kmem[cpu].lock); // 获取当前CPU对应的锁
r = kmem[cpu].freelist;// 从当前CPU的空闲链表获取第一个内存块
// if(r)
// kmem.freelist = r->next;
// release(&kmem.lock);
if(r){ // 如果有空闲内存块
kmem[cpu].freelist = r->next; // 更新当前CPU的空闲链表,跳过当前分配的内存块
}
else{ // 如果没有空闲内存块,从其他CPU窃取内存
for(int i = 0;i < NCPU;i++){ //遍历所有cpu
if(i == cpu){
continue; // 跳过当前cpu
}
acquire(&kmem[i].lock); // 获取锁
if(kmem[i].freelist == 0){ // 如果空闲链表为空
release(&kmem[i].lock); //释放锁
continue; // 去下一个cpu继续找
}
// 空闲链表不为空
struct run *tmp = kmem[i].freelist; // 获取空闲链表头指针
for(int j = 0; j < 512; j++){
// 遍历链表,tmp指向最后一个next不为空的位置
if(tmp->next)
tmp = tmp->next;
else
break;
}
kmem[cpu].freelist = kmem[i].freelist; // 将找到的这个空闲链表头转移到当前 CPU
kmem[i].freelist = tmp->next; // 更新被窃取的cpu的空闲链表
tmp->next = 0; // 断开窃取的内存块与原链表的连接
r = kmem[cpu].freelist; // 获取空闲内存块
kmem[cpu].freelist = r->next; // 更新链表
release(&kmem[i].lock); // 释放窃取的cpu的锁
break;
}
}
release(&kmem[cpu].lock); // 释放当前cpu锁
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
|
测试结果
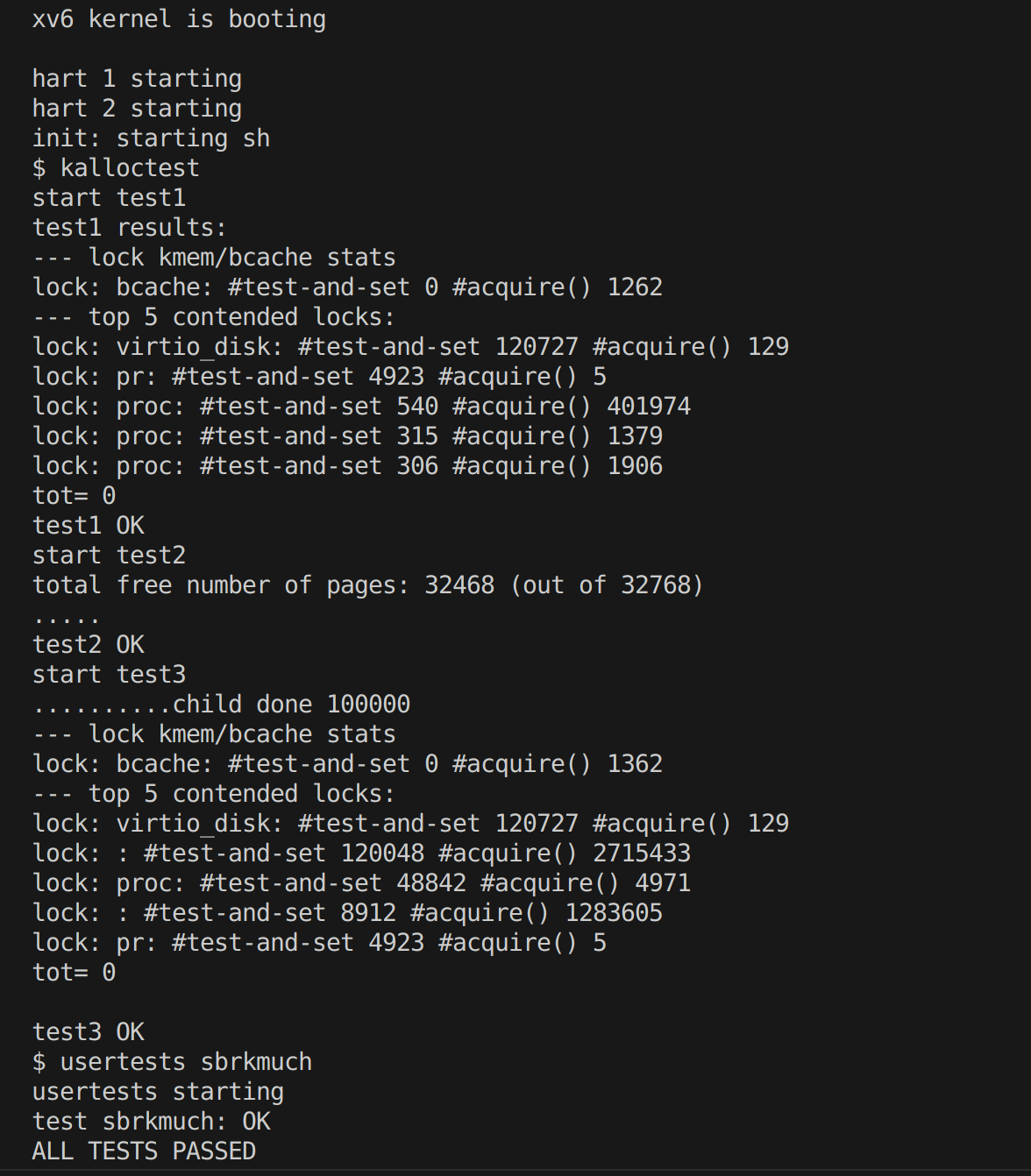

… …

Buffer cache
实验任务
原始代码使用单个全局锁(bcache.lock)保护所有缓存块,当多进程同时访问文件系统时出现严重锁竞争。bcache.lock 锁用于保护磁盘区块缓存,在原本的设计中,由于该锁的存在,多个进程不能同时操作(申请、释放)磁盘缓存。
bcachetest 模拟创建多个进程,反复读取不同的文件,以在 bcache.lock 上产生争抢。实验需要我们修改块缓存,使得在运行 bcachetest 时,bcache 中所有锁的 acquire 循环迭代次数接近于零。
源码分析
通过阅读实验要求,发现有关buffer cache的代码主要在kernel/bio.c 中。其中主要接口包括:
bread:获取并读取磁盘块到缓冲区bwrite:将缓冲区的内容写回磁盘brelse:释放缓冲区并更新其在LRU链表中的位置bpin 和 bunpin:分别增加和减少缓冲区的引用计数
内部实现包括:
binit :初始化函数,用于设置缓冲区缓存的基本结构,包括初始化自旋锁、双向链表和缓冲区的睡眠锁bget :在缓冲区缓存中查找或分配一个缓冲区
数据结构:
1
2
3
4
5
6
7
8
9
10
|
// kernel/bio.c
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
|
原版 xv6 的设计中,使用双向链表存储所有的区块缓存
在读写硬盘的时候,需要通过 bread() 函数得到相应的缓存:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
|
首先调用了bget()用于判断是否之前已经缓存过了硬盘中的这个块:如果有,那就直接返回对应的缓存;如果未缓存,则分配一个最近最少使用的未使用缓存。阅读源码:
可以看到,所有的缓存被串到了一个双向链表里。链表的第一个元素是最近使用的,最后一个元素是很久没有使用的。
每次 bget() 的时候会先遍历一遍链表,检查当前块是否已经被存到缓存里了。如果没有,那就会从后到前遍历链表(意味着是从最久没有使用的开始找),找到第一个引用计数为 0 (代表没有程序正在使用这个块)的缓存作为当前块的缓存。
这就造成了,在任何时候想要分配缓存,都需要竞争这个链表的锁。
可能你会想到使使用前一个实验的方法来优化,但把缓存分配到不同核心的方法是行不通的。因为分配页帧和回收页帧的时候,只需要有一个核心参与,而且分配后某个页帧只会被一个进程访问。
而分配出去的块缓存可能会被不同进程访问。比如不同的进程可以访问和写入同一个块缓存。如果预先按照核心分配缓存,有很大概率进程需要的缓存不属于当前核心。那就需要去一个一个的遍历别核心的块缓存,造成性能下降。(不过如果每个块缓存单独持有一个锁,粒度更小了会不会性能更好点)。
实验描述中给我们的提示是实现一个散列表。散列表会把块号映射到块缓存的桶,那么只有两个进程试图操作同一个桶中的块缓存,才会造成竞争。而且在查找所需块缓存时页不需要遍历所有的缓存,只需要遍历对应的桶。
当然,在对应桶中没有足够缓存时,我们可以像在 kalloc() 中一样,从别的桶中偷缓存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
|
实验思路
- 与
kalloc中一个物理页分配后就只归单个进程所管不同,bcache 中的缓存块实现的是真正的共享。所以不能使用kmem 中为每个 CPU 预先分割一部分专属的页的方法。
- 通过实验要求提示:”We suggest you look up block numbers in the cache with a hash table that has a lock per hash bucket. “主要解决锁竞争的思路是:使用哈希桶降低锁的粒度,用更精细的锁来降低出现竞争的概率。
- 首先根据提示:“It is OK to use a fixed number of buckets and not resize the hash table dynamically. Use a prime number of buckets (e.g., 13) to reduce the likelihood of hashing conflicts. ”,设定固定质数(13)个数的哈希桶,将全局链表替换为哈希桶结构,把块缓存号映射到块缓存的桶,每个桶有独立的锁。这样只有两个进程试图操作同一个桶中的块缓存,才会造成竞争。
- 初始化:需要初始化每一个桶的双向链表及其对应的锁。与上一个实验类似,使用
snprintf 为每个桶锁生成名称。开始先将所有缓冲区初始化到bucket[0]中
- 依次根据数据结构的改变修改其他函数的具体实现:
bget :
- 根据
blockno计算哈希值,在对应的桶中查找缓冲区。与原本的逻辑大致相同,查找时需要启用锁保护。
- 需要检查两次目标桶,一次五全局锁,一次有全局锁(若其他线程在第一次释放锁后缓存了该块,此次能检测到),确保只有一个线程能执行缓存分配,防止重复缓存。
- 修改分配机制:如果在目标哈希桶中找不到,则遍历所有哈希桶,寻找未使用的缓冲区。找到未使用的缓冲区后,将其从原桶中移除,并重新插入到目标桶中。根据提示“In
bget you can select any block that has refcnt == 0 instead of the least-recently used one. ”,放弃LRU,任意选择refcnt==0的缓冲区。
brelse:与原本逻辑大致相同,加入计算哈希值,操作对应桶即可。bpin 和 bunpin:与原本逻辑大致相同,加入计算哈希值,操作对应桶即可。
- 根据提示 “Your solution might need to hold two locks in some cases; for example, during eviction you may need to hold the bcache lock and a lock per bucket. Make sure you avoid deadlock. ”和“When replacing a block, you might move a
struct buf from one bucket to another bucket, because the new block hashes to a different bucket. You might have a tricky case: the new block might hash to the same bucket as the old block. Make sure you avoid deadlock in that case. ” 需要按桶索引顺序加锁、操作完成后逆序释放锁,并且避免在持有锁的情况下再次尝试获取其他锁,避免死锁问题。
实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
|
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKET 13 // 定义哈希桶数量(使用质数减少冲突)
struct {
struct spinlock lock; // 全局锁
struct buf buf[NBUF];
struct buf bucket[NBUCKET]; // 哈希桶头节点数组
struct spinlock bucket_lock[NBUCKET]; // 每个桶的独立锁
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
} bcache;
void
binit(void)
{
struct buf *b;
char name[32];
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
for(int i = 0; i < NBUCKET; i++) {
snprintf(name, sizeof(name), "bcache_bucket_lock_%d", i); // 锁命名
initlock(&bcache.bucket_lock[i], name); // 初始化每个桶的锁
bcache.bucket[i].prev = &bcache.bucket[i];
bcache.bucket[i].next = &bcache.bucket[i]; // 初始化空链表
}
// 所有缓冲区初始分配到桶0
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.bucket[0].next;
b->prev = &bcache.bucket[0];
initsleeplock(&b->lock, "buffer");
bcache.bucket[0].next->prev = b;
bcache.bucket[0].next = b;
}
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int hashcode = blockno % NBUCKET; // 计算哈希值
acquire(&bcache.bucket_lock[hashcode]); // 只获取目标桶锁
// Is the block already cached?
for(b = bcache.bucket[hashcode].next; b != &bcache.bucket[hashcode]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.bucket_lock[hashcode]); // 释放桶锁
acquiresleep(&b->lock); // 获取睡眠锁
return b;
}
}
release(&bcache.bucket_lock[hashcode]); //释放桶锁
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
acquire(&bcache.lock); // 获取全局锁
acquire(&bcache.bucket_lock[hashcode]); // 再次获取目标桶锁
// 重新检查目标桶(在持有全局锁的情况下)
for(b = bcache.bucket[hashcode].next; b != &bcache.bucket[hashcode]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.bucket_lock[hashcode]);
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
for(int hashcode2 = 0; hashcode2 < NBUCKET; hashcode2++) {
if(hashcode2 != hashcode)
acquire(&bcache.bucket_lock[hashcode2]); // 获取其他桶锁
for(b = bcache.bucket[hashcode2].next; b != &bcache.bucket[hashcode2]; b = b->next){ // 遍历当前桶
if(b->refcnt == 0){ // 如果找到空的
// 从当前桶移除
b->next->prev = b->prev;
b->prev->next = b->next;
// 插入目标桶头部
b->next = bcache.bucket[hashcode].next;
b->prev = &bcache.bucket[hashcode];
bcache.bucket[hashcode].next->prev = b;
bcache.bucket[hashcode].next = b;
// 设置缓冲区元数据
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
// 释放锁
if(hashcode2 != hashcode)
release(&bcache.bucket_lock[hashcode2]);
release(&bcache.bucket_lock[hashcode]);
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
if(hashcode2 != hashcode)
release(&bcache.bucket_lock[hashcode2]); // 释放其他桶锁
}
panic("bget: no buffers");
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int hashcode = b->blockno % NBUCKET; // 计算哈希值
acquire(&bcache.bucket_lock[hashcode]); // 只获取对应桶锁
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.bucket[hashcode].next;
b->prev = &bcache.bucket[hashcode];
bcache.bucket[hashcode].next->prev = b;
bcache.bucket[hashcode].next = b;
}
release(&bcache.bucket_lock[hashcode]);
}
void
bpin(struct buf *b) {
acquire(&bcache.bucket_lock[b->blockno % NBUCKET]);
b->refcnt++;
release(&bcache.bucket_lock[b->blockno % NBUCKET]);
}
void
bunpin(struct buf *b) {
acquire(&bcache.bucket_lock[b->blockno % NBUCKET]);
b->refcnt--;
release(&bcache.bucket_lock[b->blockno % NBUCKET]);
}
|
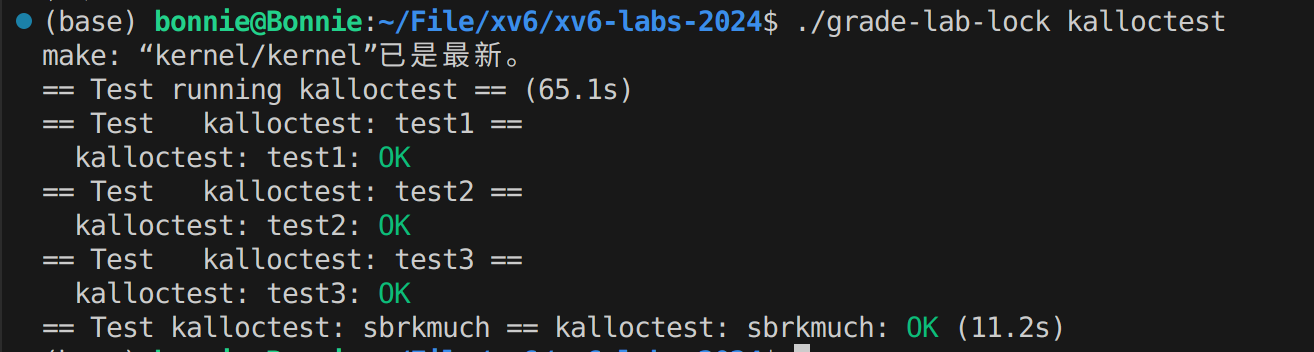
实验结果
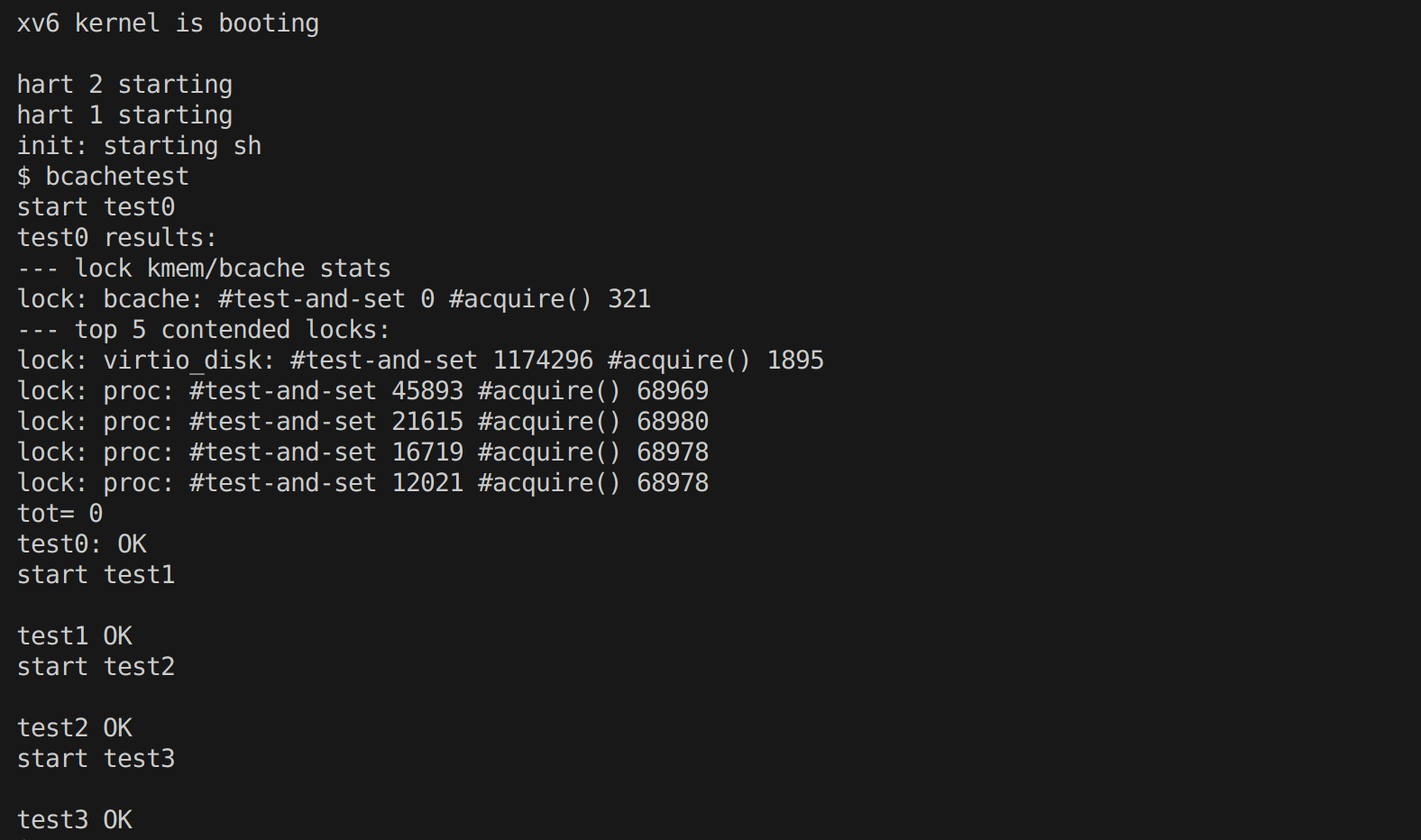

… …